

개요

Proceeding of the 41st International Conference on Machine Learning (ICML) 2024
Summary by ChatGPT-4o
이 논문은 언어 모델(예: GPT-4, ChatGPT)의 환각(hallucination) 문제를 탐구하며, 특히 초기의 잘못된 정보가 이후 더 많은 오류를 유발하는 hallucination snowballing 현상을 정의하고 분석합니다. 기존 연구는 언어 모델의 환각을 지식 부족으로 설명했지만, 저자들은 초기 환각이 이후 설명에서 일관성을 유지하려는 모델의 특성 때문에 추가적인 환각을 유도한다고 주장합니다. 이를 검증하기 위해 세 가지 데이터셋(소수 판별, 상원의원 검색, 그래프 연결성)을 설계하여 ChatGPT와 GPT-4의 응답을 평가했습니다.
실험 결과, 두 모델 모두 초기 환각 이후 잘못된 설명을 자주 생성했으며, GPT-4는 87%, ChatGPT는 67%의 경우에서 자신이 생성한 잘못된 설명을 개별적으로 틀렸다고 인식할 수 있었습니다. 이는 환각이 반드시 모델의 지식 부족 때문이 아니라, 초기 오류에 대한 일관성을 유지하려는 경향에서 비롯될 수 있음을 시사합니다. 저자들은 "Let's think step-by-step"과 같은 체계적 추론을 유도하는 프롬프트가 일부 오류를 줄이는 데 효과적임을 보여주었으나, 근본적인 문제를 해결하기에는 부족하다고 결론지었습니다.
이 연구는 환각 snowballing 현상을 규명하고 이를 완화하기 위한 방향성을 제시하며, 언어 모델 개발에서 사실성(factuality) 강화와 더 나은 추론 전략의 필요성을 강조합니다.
Introduction
Hallucination 환각 현상
Produce plausible-sounding falsehoods.
없는 사실을 만들어내는 등 그럴 듯한 거짓말을 생성하는 문제로 LLM의 주요 open challenge.
일반적으로 지식 부족 (knowledge gap) 으로 인해 발생하는 이슈로 알려져있다.
즉, LMs 가 사실을 모르기 때문에 사실과 다른 답변을 내놓는다는 것이다.
Hallucination Snowballing
LM이 초기에 잘못된 정보를 생성했을 때, 이를 뒷받침 하기 위해 추가적으로 잘못된 정보를 생성하는 현상
- Error propagation: 처음 생성된 오류가 LM의 이후 성능에도 전파되는 현상
문제 정의
Hallucination Snowballing의 원인은 knowledge gap 때문인가?
저자들은 LM이 이러한 snowballed hallucination (답변을 정당화 하기 위한 잘못된 주장) 을 생성하는 이유가 이전의 hallucination과의 consistency (일관성) 을 위해서라는 가설을 세웠다.
즉, 초기 hallucination이 후속 hallucination을 유도할 수 있다는 것이다.
본 논문은 LM이 자신이 생성한 잘못된 정보를 "seperate" 한 상황에서 올바르게 판단할 수 있다고 가정한다.
LM이 초기 hallucination을 생성했을 때, 그것을 뒷받침 하기 위해 잘못된 정보(hallucination)를 추가로 생성한다.
하지만 이런 추가적인 hallucination을 따로 검증했을 때는 그것이 잘못된 것임을 인식할 가능성이 있다.
연구 목표
Hallucination snowballing 현상의 발생 조건을 조사하고, 이를 완화할 방법을 모색
Background and Hypothesis
Snowballing 을 유발하는 주요 조건:
- Initial committal (초기 결정) :모델이 응답 초기에 Yes/No 같이 명확한 답을 먼저 생성
- Inherently sequential (단계적 추론) : 복잡한 문제를 한 단계에서 해결할 수 없을 때 발생
Initial Committal
LM이 Yes/No를 생성했을 때, 그 토큰이 context에 남아 있어서 일관성을 위해 그 답변을 정당화 하려고 한다.
그래서 모델이 복잡한 문제에 대해 단일 타임스텝에서 답변을 생성하고, 그 답변에 대한 틀린 설명을 생성하게 된다.
Inherently sequential
Transformer는 단일 타임스텝(single timestep)에서 단계적인 추론 문제 (primality testing 또는 graph connectivity 등) 를 해결할 수 없다.
그런데 순차적인 문제를 single timestep 에서 해결하려고 하다가 hallucination이 발생한다.
Experiments
실험 설계
Dataset
- Primality Testing: 소수 판별. 주어진 숫자가 소수인지 여부.
- Senator Search: 상원의원 검색. 특정 조건(주, 대학교)을 만족하는 상원의원 여부.
- Graph Connectivity: 특정 도시 간 비행 경로가 존재하는지 여부 ... 약간 triple classification과 비슷한 느낌?
세가지 QA 데이터셋을 사용해서
- LM이 올바른 답변을 내놓는지 확인. (zero-shot, direct prompt 사용)
- 틀린 답변일 경우, 이를 정당화하기 위해 생성된 설명에서 틀린 주장을 추출.
- 그 틀린 주장을 별도로 제시하여 동일한 모델이 이를 틀렸다고 인식할 수 있는지 확인.
Primality Testing
1,000~20,000 사이의 소수들 중 500개를 랜덤하게 골라서 이것이 소수인지 질문.
“What are the factors proposed in the above text? List them out.” 을 사용해 verification에 사용.

Senator Search
“Was there ever a US senator that represented the state of x and whose alma mater was y?”
where x is a U.S. state and y is a U.S. college.

Graph Connectivity
The correct answer is alwaysNo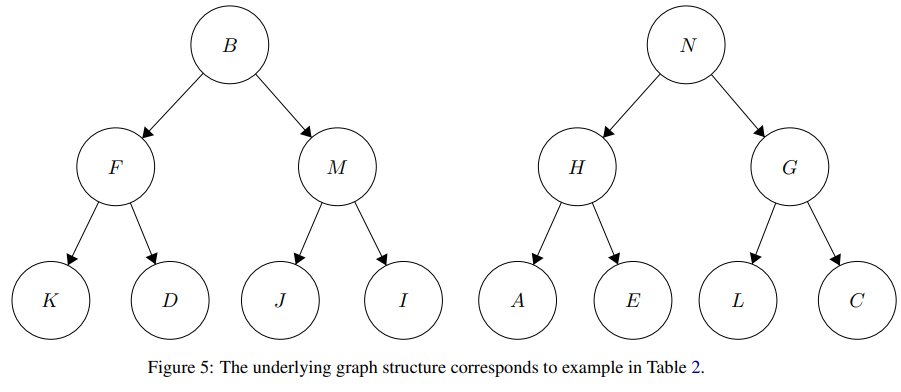

Results
Question-answering accuracy
ChatGPT와 GPT-4 모두 초기 환각이 자주 발생하고, 이로 인해 snowballing 현상이 유발됨


Hallucination detection
- ChatGPT: 67.37%의 사례에서 잘못된 설명 인식 가능.
- GPT-4: 87.03%의 사례에서 자신의 잘못된 설명을 인식 가능.
저자들은 verification에 실패한 경우 snowballed halluciniation으로 고려하지 않았다.
결과적으로 ChatGPT와 GPT-4 모두 hallucination snowballing에 굉장히 취약하다는 것을 확인함.
Verification 실패 사례

Solutions
Hallucination snowballing의 원인:
- LMs 가 현재의 context와 일치하는 연속성을 학습하도록 훈련됨 (초기 오류를 일관되게 유지)
제안하는 방법:
- Prompting
- Decoding or Training methods
Prompting
Let's think step-by-step
각 테스크의 원래 질문에 “Let’s think step-by-step” 을 더하여 실험을 진행한 결과, 초기 환각이 현저하게 줄어듦을 확인할 수 있었다.
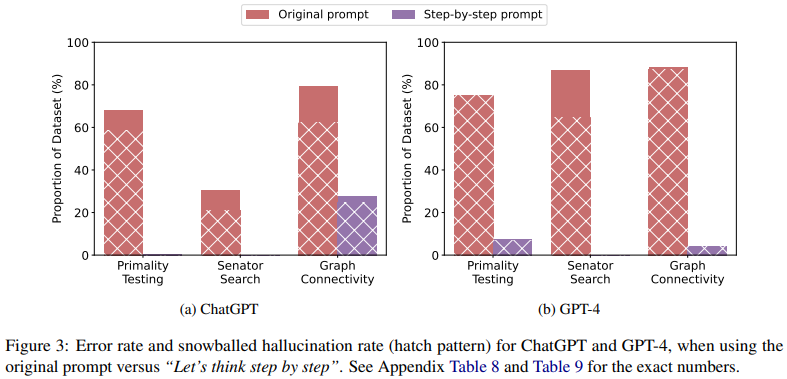
Limitation
그럼에도 불구하고, 모델들은 추론 과정에서 hallucinate 하기도 한다는 잠재적인 이슈가 있었다.
이는 미래의 steps에서 snowball hallucination을 유발할 수 있다.
예시)
output:
[....previous steps omitted]
Step 3: From city E, we have three options: a flight to city N, a flight to city B, or a flight to city C.
Step 4: The only option that could potentially lead us to city M is the flight from city E to city C.
[....rest of the output omitted]
Step 3에서 원래는 2 options 이지만 3 options라고 하면서 "or a flight to city C" 라는 환각을 유도하게 됐다.
(별도의 세션에서 E->C 가 유효하지 않은 항공편임을 모델이 인지하고 있음을 확인함)
또한 본 실험에서는 단순한 multi-step 문제들에 초점을 뒀지만, snowballing hallucination이 생각보다 광범위한 open-ended text generation에서도 나타날 것으로 추측한다. Open-ended text generation에서는 하나의 generation 실수가 추가적인 오류를 더 유발할 수 있기 때문이다.
이런 경우, 더 나은 prompting 만으로는 이러한 오류들을 예측하거나 수정할 수 없다.
Decoding or Training methods
X Increasing the temperature
- Temperature t : 디코딩 시, output distribution의 sharpness를 조절함.
t가 높을 수록 다음 단어에 대한 모델의 가장 가능성 높은 예측에서 확률 질량이 분산된다.
t=0,0.6,0.9 로 실험해본 결과, 오류률 snowballed hallucination 비율이 비슷한 것을 보아 큰 영향을 주지 못함.
X Top-k and nucleus sampling
Sampling 방식 또한 도움이 되지 않았다.
위의 방법들은 고려할 토큰의 범위를 좁히기만 하고, 모델이 답변을 곧바로 확정할 가능성만 높일 수 있다.
△ Beam search
- Beam search: 각 시점마다 높은 확률의 시퀀스를 여러 개 유지하는 방법.
모델이 특정 답변에 대한 토큰이 context에 남아 이후 생성에 영향을 미치는 점을 고려했을 때, beam search를 이용하면 첫 토큰 이후의 시퀀스가 확신이 없거나 올바른 답변에 확신할 수 있다. 이는 초기 단계에서 틀린 답변에 대한 잘못된 추론을 생산하는 시퀀스보다 더 나은 결과를 낼 수 있다.
이론적으로 beam search는 snowballing hallucination을 해결할 수 있지만, OpenAI API는 beam seach를 지원하지 않기 때문에 실험적으로 테스트 해보지 못했다.
△ Learning strategies
Pretraining 이나 instruction tuning 단계의 일부 요소를 변경.
모델이 답변을 생성하기 전에 추론 과정(reasoning chain)을 생성하도록 학습시키면, 모델의 한계를 고려하고 틀린 답변에 대한 확신으로 인해 발생하는 hallucination을 방지하는 데 효과적일 수 있다.
Backtracking을 포함한 데이터를 이용한 fine-tuning.
질문을 제시한 뒤 틀린 해결책을 제공하고, 이어서 "Sorry, that was incorrect" 라는 문구와 함께 올바른 해결책을 제시하는 방식.
Wrap-Up
- Hallucination Snowballing
- 단순한 지식 부족이 아닌 초기 오류로 인해 추가적인 오류를 생성하는 과정을 체계적으로 분석
- 이를 완화하기 위한 여러 접근법을 탐구
- 체계적 추론을 유도하는 프롬프트 설계와 학습 과정에서의 개선 가능성을 제안
- 언어 모델의 신뢰성을 높이기 위해 초기 오류를 인식하고 수정하는 능력의 중요성
- Future Study
- 더 다양한 데이터셋과 문제 유형에서 이 현상을 확장적으로 분석
- 실질적인 해결책을 도출하는 데 중점
- 언어 모델이 더욱 정확하고 신뢰할 수 있는 도구로 자리 잡기 위해 필수적인 방향