Factorization Machines (FM)
FMs은 real-valued features를 latent factor space에 맵핑하는 일반적인 지도 학습 모델이다.
MF와 FM의 목표는 둘다 input에 대해 파악되지 않은 rating을 예측하는 것이다.

일반적인 MF 알고리즘들은 더 일반적이거나 유연한 FM 모델 클래스의 특수한 케이스로 재구성 할 수 있다.
MF의 latent space는 아이템에 대한 유저의 rating에 대한 것을 담았다. 이 경우 유저와 아이템의 수가 많으면 많은 weight를 사용해 오버피팅이 될 가능성이 높다.
FM의 latent space는 아이템과 유저에 관한 정보를 one-hot encoding 하고 concat 하고 부가적인 features를 추가하여 sparse한 메트릭스를 만든다.

위의 모델 파라미터들을 포함하여 최적화를 진행한다
FM을 적용할 수 있는 예측 테스크 :
1. Regression
\(\hat{y}(x)\) 는 바로 predictor와 optimization criterion 으로 사용 할 수 있다.
예시. \(\mathcal{D}\) 에 대한 least square error
2. Binary classification
\(\hat{y}(x)\) 이 사용되고, 파라미터들은 hinge loss 또는 logit loss를 위해 최적화 된다.
3. Ranking
벡터 x 는 \(\hat{y}(x)\) 의 점수에 의해 정렬되고, 최적화는 pairwise classification loss와 함께 instance vector 쌍 \( (x_{(a)}, x_{(b)}) \in \mathcal{D} \)에 대해 진행된다.
L2 Regularization을 이용한 Objective

Higher-order FM
Second-order FM (large potentional candidate)는 higher-oreder FM(2개 이상일 때)으로 일반화 할 수 있다.
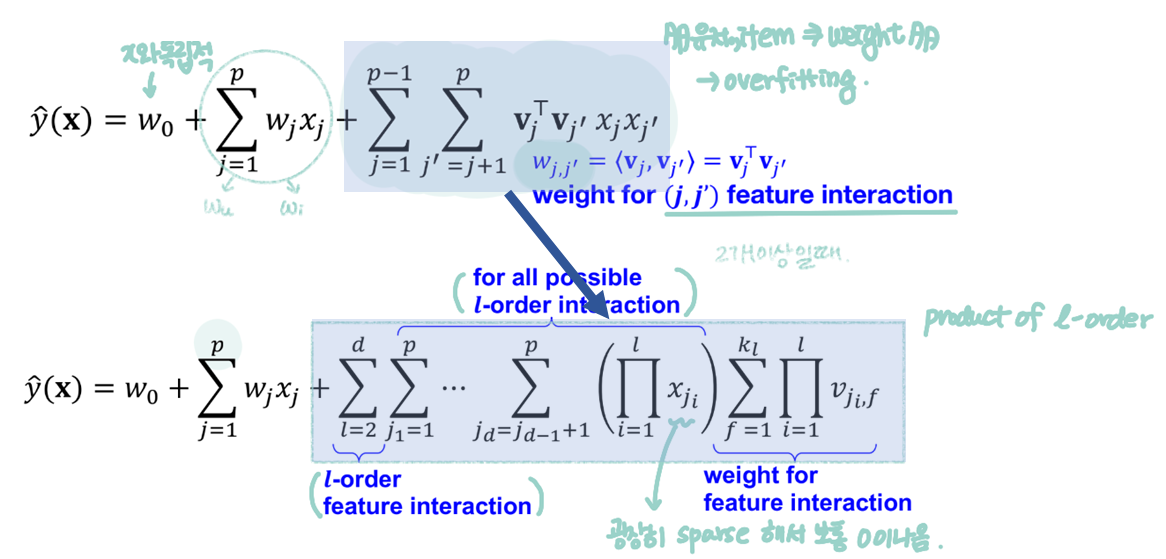
일반적으로 higher-order interaction은 추정하기 어렵지만 higher-order FMs를 통해 보다 쉽게 접근할 수 있다.
대부분의 공식들과 알고리즘은 바로 higher-order FMs로 전환할 수 있다.
왜냐하면 Higher-order FMs는 second-order FMs와 multilinearity(다선성)을 공유하기 때문이다.
Optimization for FM
SGD



ALS / CD



Factorization 모델의 FM 표현
Attribute-Aware Models
유저와 아이템에 대한 attribute information을 추천시스템에 통합하기 위해서,
장르나 배우 같은 아이템이나 유저의 속성을 input vector x에 추가한다.

유저 u의 아이템 i 에 대한 rating 예측인 input vector x는 유저 u에 대한 원핫 인코딩 벡터와 아이템에 대한 속성 정보를 concat한 것이다.
\(\hat{y}(x)\) = (유저 u에 대한 가중치) + (아이템 bias) + (속성 맵핑) + (pairwise 아이템 속성)